Write和Edit工具的实现细节
TOCTOU防护
该功能是Time-of-Check to Time-of Use的缩写,中文叫“检查时刻到使用时刻的竞争条件”,是写入工具和修改工具执行前的安全检查之一
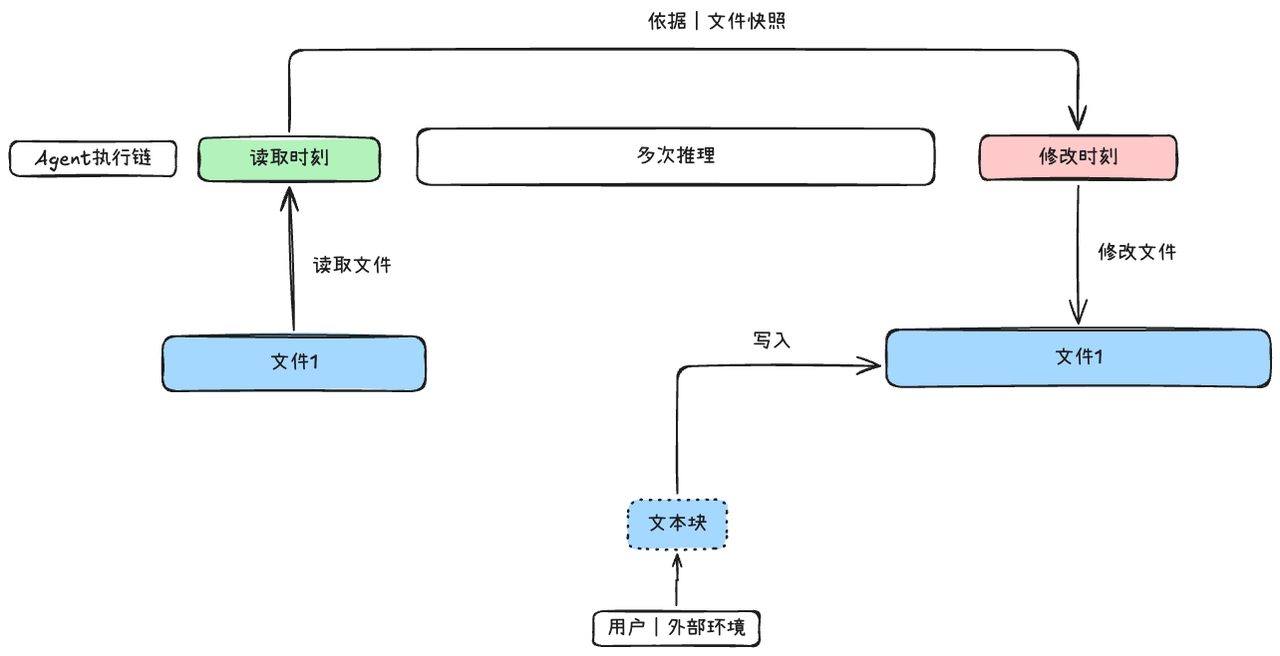
在Agent执行过程中,当Agent先调用读取工具获得文件内容,经过很多轮的推理,再调用写入工具,在多轮推理期间文件可能已经用户或者其他的外部环境修改了,那么Agent所依据文件旧内容推理得到的调用结果,也就是调用写入工具时的参数是完全错误的,那么该工具执行命令不应该被执行。应该让模型重新读取新内容进行推理
TOCTOU设计目的是:保证模型在修改或写入文件的时候,其读取推理时的文件内容是最新的。
如果没有TOCTOU防护来保证模型读取的文件快照是最新的话,那么修改行为会错乱,写入行为会将文件新内容覆盖掉,导致整个写入工具以错误意图执行
该功能的核心代码主要是:
// 1. 校验阶段:文件是否被读取过
const readTimestamp = toolUseContext.readFileState.get(fullFilePath)
if (!readTimestamp || readTimestamp.isPartialView) {
return { result: false, message: 'File has not been read yet...', errorCode: ... }
}
// 2. 校验阶段:检查 mtime
const lastWriteTime = getFileModificationTime(fullFilePath)
if (lastWriteTime > readTimestamp.timestamp) {
return { result: false, message: 'File has been modified since read...' }
}文件读取验证:先验证文件是否被读取过,通过读取工具中的文件读取信息中是否存在相应的文件路径来判断
读取时间验证:再验证文件当前的修改时间是否大于读取信息中的修改时间,如果大于说明文件在模型读取之后被修改过,所以模型读取的文件内容是旧的,需要提示模型重新读取该文件,以新内容作为推理条件重新调用写入工具
🌴 这个设计的核心是:读取工具的调用要保存文件读取信息到内存中,否则该TOCTOU的设计是没有任何输入进行判断的
如果在Agent的工具设计中,只用一个Bash工具来完成对文件的读取和查询操作,并没有设计单独的读取文件内工具,那么也应该保证在文件写入和修改之前,相关的文件内容被正确加载进入到Agent推理的上下文中去
2、文件原子写入
在对文件进行写入操作的时候,有可能会因为程序的崩溃和意外情况的出现,导致写入操作进行到一半中断,那么这个时候很可能出现两种错误情况:文件内容空白或内容不完整
所以我们要设计文件写入原子化操作:文件要不成功完整写入,要不就回退到旧的状态
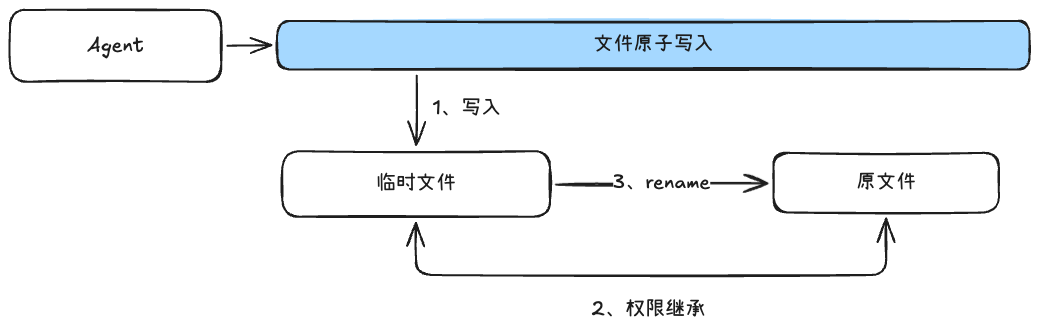
核心的代码设计思路:
//1、创建临时文件路径
const tempPath = `${targetPath}.tmp.${process.pid}.${Date.now()}`;
//2、向临时文件写入内容,并将内容从内存缓存中推入磁盘
writeFileSync(tempPath, content, { encoding, flush: true });
//3、保留原文件的权限
chmodSync(tempPath, targetMode);
//4、执行rename替换
renameSync(tempPath, targetPath);先创建临时文件的路径
向临时文件中写入内容,同时强制将内容从内存缓存中直接推入到系统磁盘中
保留原文件的权限,将临时文件的权限和原文件的权限设置一致
执行文件重命名原子级的替换
3、FileWriteTool工具
写入工具目前的执行结果有两种,当文件不存在的时候,那么就是创建文件之后写入,当文件存在的时候,那么就是直接覆盖原文件的内容
工具的定义如下:
export const FileWriteTool = buildTool({
name: 'Write',
searchHint: '创建或覆盖文件',
// 工具描述(给模型看的系统提示)
description: "将文件写入本地文件系统 \n 修改现有文件时请优先使用编辑工具 —— 仅当创建新文件或完全重写文件时才使用此工具 \n 在覆盖文件之前,必须先读取文件的内容",
inputSchema: z.strictObject({
file_path: z.string().describe('文件的绝对路径(必须为绝对路径,不能为相对路径)'),
content: z.string().describe('要写入文件的内容'),
}),
// ...其他的工具定义,按需设计
});工具定义的核心参数有两个:
file_path:要写入内容的文件路径,使用绝对路径
content:要写入文件的完整内容,由大模型生成
那么工具的返回结果如下:
{
filePath:string
type:'create' | 'update'
}FileWirteTool工具执行结果返回的也很简单:filePath和type,一个是文件路径,一个是操作类型,是覆盖还是新创建的文件
如果你想要做的更好一些,或者模型的能力比较弱一点,那么你可以将这个参数补充作为完整的文本语义输入给模型
export function mapToolResultToToolResultBlockParam({ filePath, type }, toolUseID) {
switch (type) {
case 'create':
return {
tool_use_id: toolUseID,
type: 'tool_result',
content: `File created successfully at: ${filePath}`,
}
case 'update':
return {
tool_use_id: toolUseID,
type: 'tool_result',
content: `The file ${filePath} has been updated successfully.`,
}
}
}这样做会让工具的输出对于模型在上下文的推理中更加的有效和减少歧义
关于该工具的执行函数的实现,逻辑不复杂:
从file_path参数中提取出来目录路径,对于目录路径进行判断,如果文件目录不存在就创建,并进行skill的发现
根据file_path文件路径读取文件,获取文件内容,如果文件内容为空,那么type的值为create、反之就是update
执行TOCTOU检查,保证模型推理时读取的文件内容是新的
执行文件的原子化写入
更新文件读取信息,之后将工具结果返回
3.1、动态发现加载Skill
🌟 在ClaudeCode的对于FileWirteTool工具的设计思路中,有一个亮点的设计,也是一个小巧思,动态加载写入文件父目录下的Skill
我们直接找一个场景来说,会更容易理解一些
my-project/
├── .claude/skills/ // 根目录 skill(启动时已加载)
│ └── general-coding.md
├── packages/
│ ├── backend/
│ │ ├── .claude/skills/ // 后端专属 skill(启动时没扫到)
│ │ │ └── api-rules.md
│ │ └── src/
│ │ └── user.ts // 你在这里执行 Write
│ └── frontend/
│ ├── .claude/skills/ // 前端专属 skill(启动时没扫到)
│ │ └── react-rules.md在Agent对于Skill加载功能的实现中,Agent启动时,会读取项目级和用户级的skill文件,项目级中读取到的是工作空间的根目录下的skill文件
在这种实现思路下,你会发现我们只读取了工作空间的根目录的skill,那如果项目是一个微服务类型的,其会有多个子项目,每一个子项目又存在skills,
你如果单独以工作空间的方式打开每一个子目录,那么当然会正常加载,但是如果你打开微服务的根目录,那么子项目中的skill就不会加载进入Agent中
这不是一个设计缺陷,更多是从Agent的加载性能考虑的,如果在Agent初始化阶段加载全部的子目录skill,是有可能会导致Agent启动缓慢同时,内存占用拉满
所以ClaudeCode设计做法更优雅合理一些,在写入工具执行过程中进行判断,然后向上层目录查询,发现并动态加载相应子目录下的skills
从上面的案例你可以看到,如果我们向user.ts文件写入内容,那么向上查询的时候,就可以异步将backend子目录下的skills动态加载进来,而不是在一开始就加载backend的skills
4、FileEditTool工具
文件修改工具的核心实现是字符串替换,采用连续多行文本整块的替换,比较麻烦的就是一些特殊字符的处理,删除、增加、修改三种操作本质上都是“替换”
如果是对文件进行部分内容删除的操作,那么在替换方式中的实现逻辑就是:原本那块文本是5行,替换为4行(去掉了目标行),以少的替换多的来实现删除操作
如果是对文件进行内容的增加操作,那么在替换中的实现逻辑就是和删除相反的,原本那块文本是3行,替换为新的6行(插入了新内容),以多的替换少的来实现增加操作
如果是对文件进行修改操作,那么就是新的文本替换旧的文本
//FileEditTool工具的定义
export const FileEditTool = buildTool({
name: 'Edit',
searchHint: '修改文件内容',
description:getEditToolDescription(),
inputSchema: z.strictObject({
file_path: z.string().describe('文件的绝对路径(必须为绝对路径)'),
old_string: z.string().describe('文件中要被替换的原始文本'),
new_string: z.string().describe('用于替换的新文本'),
replace_all: z.boolean().default(false).optional().describe('是否替换所有匹配项(默认 false)'),
}),
});
//FileEditToll的工具描述
export function getEditToolDescription() {
return `
在文件中执行精确的字符串替换
用法:
- 在编辑之前,你必须在本轮对话中至少使用一次 \`Read\`工具。如果你未读取文件就尝试编辑,此工具会报错。
- 编辑来自 Read 工具输出的文本时,确保保留行号前缀之后的精确缩进(制表符/空格)。行号前缀格式为:行号 +制表符。其后的所有内容才是需要匹配的实际文件内容。切勿将行号前缀的任何部分包含在old_string 或 new_string 中。
- 始终优先编辑代码库中的现有文件。除非明确要求,否则不要编写新文件。
- 仅在用户明确要求时才使用表情符号。除非被要求,否则避免在文件中添加表情符号。
- 使用最小的、明显唯一的 old_string —— 通常 2-4行相邻代码就足够了。当少量上下文已能唯一标识目标时,避免包含 10 行以上的上下文。
- 如果 \`old_string\`在文件中不唯一,编辑将失败。提供更长的字符串并附带更多上下文以使其唯一,或者使用\`replace_all\` 更改 \`old_string\` 的每一处实例。
- 使用 \`replace_all\`在整个文件中替换和重命名字符串。例如,如果你想重命名某个变量,此参数非常有用。
`;
}这个FileEditTool工具的返回对象属性如下:核心就是文件路径和替换行为的返回
{
filePath:string
replaceAll:boolean
}当然这里也是如此,你如果需要返回给模型的信息更加详细一点,可以考虑转换为更语义化一点
export function mapToolResultToToolResultBlockParam(data, toolUseID) {
const { filePath, replaceAll } = data
if (replaceAll) {
return {
tool_use_id: toolUseID,
type: 'tool_result',
content: `The file ${filePath} has been updated. All occurrences were successfully replaced.`,
}
}
return {
tool_use_id: toolUseID,
type: 'tool_result',
content: `The file ${filePath} has been updated successfully.`,
}
}该工具的执行函数的实现逻辑,和上面的FileWriteTool差不多:
对于文件路径中的目录进行判断,不存在就创建一个新目录,同时发现并异步加载skill
读取当前文件,文件存在将返回内容,文件不存在就返回空字符串,工具继续向下执行
进行TOCTOU的检查,保证模型推理时读取的文件内容时最新的§
进行两种双引号规范化的匹配检查,
进行替换,获取替换之后的文件新内容,并返回Diff
执行文件内容原子化写入
更新文件读取信息,之后将工具结果返回(如果UI要渲染Diff,那么Diff也要返回)
🌟关于Diff的生成,可以使用相应的库就可以直接生成, 一般使用最多的就是jsdiff库
4.1、引号规划化检查
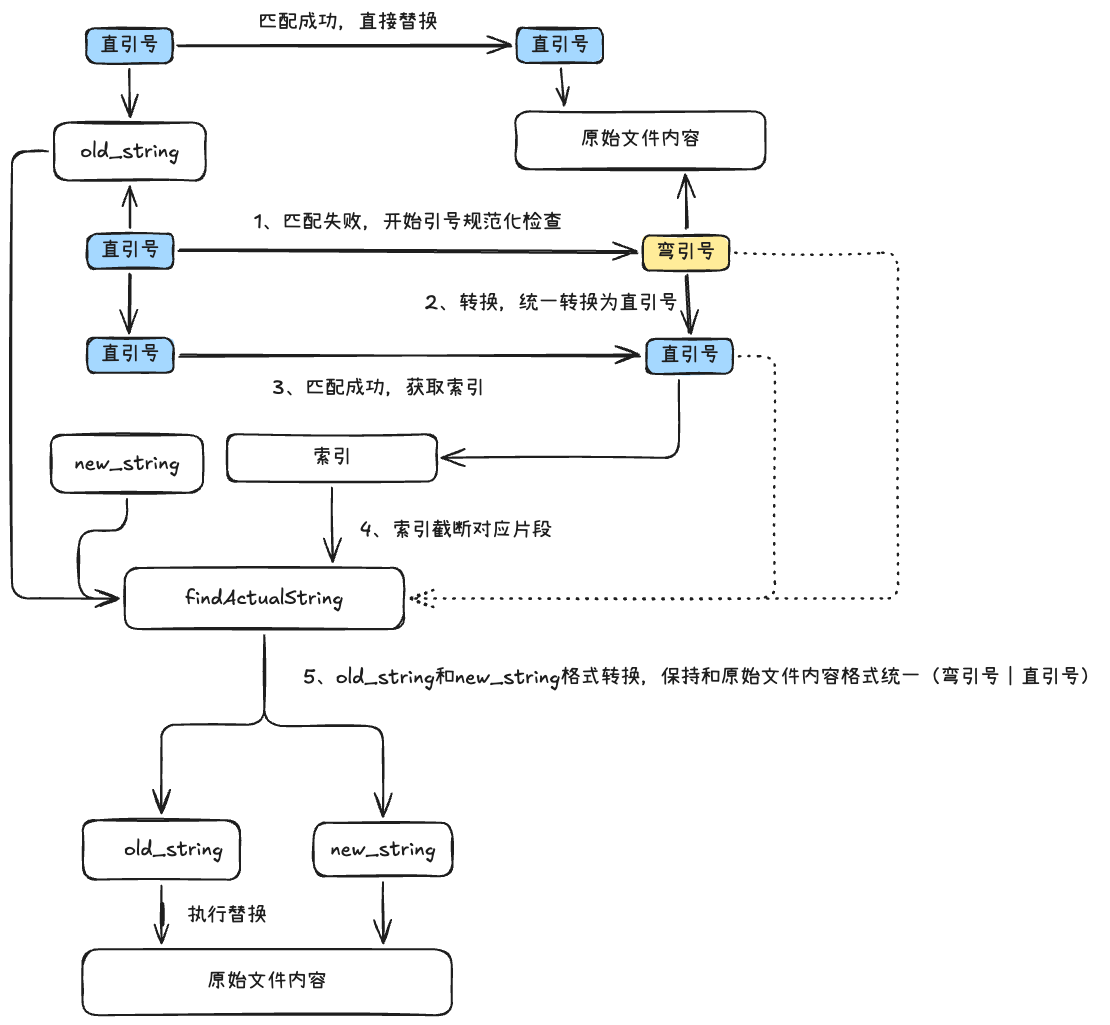
使用old_string进行字符精准匹配失败之后,就进行下一步的引号规范化检查
先统一引号格式,将old_string转换为直引号,将原始文件内容也转换为直引号,进行匹配
匹配成功之后,从转换之后的文件内容中获取到索引,用该索引从原始文件内容中截取对应片段(直引号或弯引号),赋值给
findActualString将old_string转换为
findActualString、将new_string也转换为findActualString格式之后对于原始文件内容进行替换
4.2、文件内容替换
在替换的过程中,有一种特殊情况需要单独处理,就是new_stirng为空字符串的时候,也就是删除操作
这种情况下,要注意换行符的处理,删除字符串的同时,也要删除原字符串中留下的换行符
原始文件内容:'bar\nfoo'
工具执行的参数:old_string:'bar'、new_string:''
如果没有特殊处理,替换之后剩下的是:'\nfoo',存在一个换行符
用户期望的是,替换之后剩下的是:'foo'所以这种情况要特殊处理一下,核心代码就是判断之后,单独处理
if(newString===""){
const stripTrailingNewline =
!oldString.endsWith('\n')&&originalContent.includes(oldString+'\n')
newContent=stripTrailingNewline
?replaceFileContent(originalContent,oldString+'\n',newString)
:replaceFileContent(originalContent,oldString,newString);
}