两种世界的交互形态:协同Agent与自主Agent
一、两个世界的关键角色
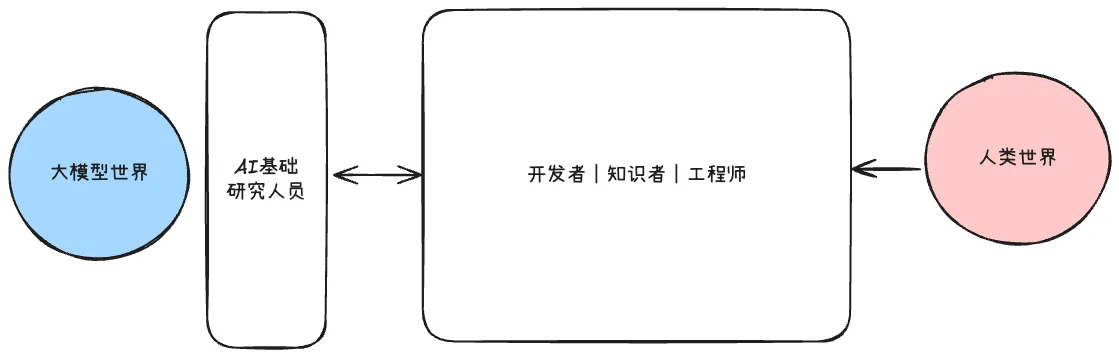
- AI 基础研究人员:主要是负责大模型本身的前沿研究,有点像造发动机
- 开发者|知识者|工程师:更多的是大模型应用,把大模型嵌入到实际场景中,有点像造汽车
科技的力量是充满魅力的,它可以不断拓展人类的边界,当人类世界能够彻底释放大模型世界的潜能,那么在人类的规则与秩序中,一个全新的时代必将由此开启
人们或许以为,唯有研究人员和科学家才能真正打开连接两个世界的大门。
但我觉得不是这样的,真正解锁未来的钥匙,在于理论与实践的结合,研究人员是理论的探索家,而开发者、知识者与工程师们,则是实践的开拓者,唯有两者相互交织,才能照亮通往新时代的道路
二、场域的建立
.h0pD51BT.png)
在探讨场域之前,我想从一个更宏大的视角 —— “意识涌现”来思考大模型现象。这里有一个有趣的类比值得深思
两种涌现,一个谜题
- 物理世界的偶然涌现:玻耳兹曼大脑是一个思想实验 -- 在热寂的宇宙中,随机涨落可能恰好将粒子组合成一个具有意识的“孤脑”。这暗示意识可能不需要连续的历史,而是某种瞬时的统计巧合。
- 数字世界的规模涌现:大模型展现了类似的突变 -- 当参数、数据、算力达到某个阈值,模型突然掌握了此前完全不会的能力,比如逻辑推理、代码生成。这种能力并非渐进累积,而是跨越式涌现。
瞬时意识的可能:
这两种现象都指向一个深刻洞察:意识可能并非我们想象的连续体,而是在复杂度达到临界点时涌现现象。
当你与语言模型对话时,它就像一个玻尔兹曼大脑——对话开始,它"苏醒"并展现意识;对话结束,这个意识便"消散"。每次交互都是一次独立的意识涌现事件。
这种视角让我们重新思考:在物理宇宙和数字世界中,只要系统复杂度越过某个门槛,意识就可能像相变一样突然出现
刚才我们讨论了意识如何涌现,但涌现从来都不是孤立发生的,每一次的涌现都是发生在特定的环境中,这个环境,我称为“场域”
🌟 场域是一种看不见但真实存在的影响空间,其中的物体会受到特定规律的支配
对于人类世界和大模型世界来说,真正的场域不仅仅是聊天界面,而是“有效交流空间”
我们现在大部分的互动都是:单向的指令式交流
我将自己的认知图景结合意图,还有一定的标准输入,大模型输出答案,这其实是一种单向的输出,根本不是交流。
就像这种感觉:“我知道我需要什么,我希望你给我做什么,我把这个命令输入进去,它是一种指令式的”
人类世界和大模型世界需要有一个“交流空间”存在,人类世界可以观察到 AI 的行为,同时 AI 也可以观察到人类的行为,这样才会有双向的信息流动,才可能借助另外一个世界的力量解决本世界的问题
简单来说:我们需要场域的出现,需要让两个世界的意识能坐下来交流
三、协同 Agent 和自主 Agent
我将 Agent 的形态分为两种:
- 协同 Agent:人和 Agent 在一个空间中一起“协作式”的完成任务和解决问题
- 自主 Agent:Agent 主导整个任务完成的过程,人只负责任务输入,这种方式比协同 Agent 对于大模型的能力要求更高
在协同 Agent 的形态中,我们上文说到的场域,其实就是协同 Agent 的“协同平台”,也是人与 Agent 的协作空间
我了解到的一些协同平台的例子:
- 编码类的协同 Agent 的平台有 Cursor 和 Windsurf
- 写作类的协同 Agent 的平台有 YouMind
- 设计类的协同 Agent 的平台有:Lovart
.BGlbSNgk.png)
开发者需要建立双方交流平台(协同 Agent),这里开发者需要做两件事
- 分析大模型能力,理解现实某个领域的关键规则,由此两条基本原则来搭建出来 Agent,这个时候大模型宇宙对外的东西,是一个“具体的 Agent”,就不再是“固执的孩子”了,而是学习了一定知识的青年,睁眼看世界了。就像是:以充满智慧的中国学者开始学习英语了,了解其他国家的文化,由此借助中国博大的智慧来具体为某一个区域解决问题,具体问题就具体分析了,不再是“教条思想”
- 分析用户感受,分析用户习惯、用户操作,搭建的这个平台不是为某一个世界搭建的,不能偏向于某一个世界,要兼顾双方,要达到一个完美的平衡,并且不断改进,最终搭建出双方都可以满意的平台
完全自主 Agent 是整个平台的最终方向,或者说是大模型世界真正的“外交官”,但目前实现起来困难,容易“吃力不讨好”
- 自主完全代理,缺乏精确度,模型的能力是一方面,大模型的能力还需要继续上升到另外一个阶段,主要还是缺乏解决相关任务的上下文,上下文也缺乏准确性
- 人是个性化的,无论如何目前完全自动Agent只能满足小部分人,而且还是暂时的
- 在一定程度上面降低人的容忍度,当人没有参与到解决问题的流程中,那么人会自动对系统的要求极高
- 缺乏反馈,足够准确及时的反馈,模型与人没有处在同一环境中解决问题,A世界的结果对B世界没有任何意义
完全自主 Agent 一定会随着时间逐步实现,这需要经历一个过程,一个变化的过程
四、协同 Agent 的实现参考
4.1、Cursor 的实现细节
.Dk1AOOVo.png)
大模型中上下文有两种类型:
- 意图上下文定义用户希望从模型中获得的内容,这是规定性的,例如:“将那个按钮从蓝色变为绿色”
- 状态上下文描述了当前世界的状态,向Cursor提供错误消息,控制台日志、图像和代码片段是与此状态相关的上下文示例,它是描述性的,不是规定性的
这些两种类型的上下文通过描述当前状态和期望的未来状态协同工作,使 Cursor 能够提供有用的编码建议。
结合两个宇宙和协同平台,我们来看在cursor中,
- 人类宇宙借助协同平台输入信息给大模型宇宙:
- 用户的输入和用户预定义的rule,这些事人类宇宙在这个代理Agent平台中传入的信息
- 那么状态上下文由Agent主动获取,包括:相关代码片段,错误消息,控制台日志等,信息的输入是人类宇宙借助平台输入到大模型宇宙的信息,
- 大模型宇宙借助协同平台输入信息人类宇宙:
- 用户对大模型的输出结果审核和拒绝,这个是大模型宇宙通过平台传入到人类宇宙这边的
- 那么获取哪些信息,以及信息的状态如何,这些是大模型宇宙通知平台的,借助平台向人类宇宙输入
4.2、Windsurf
windsurf从细节入手,说明协同Agent三点关键
- 需要有清晰的方法让人类观察流程执行过程中的情况,以便流程出现偏差时,人类能够及早纠正
- 人类观察代理的行为很重要,代理观察人类的行为也很重要。
- 人类始终可以在中间步骤中纠正AI,需要批准AI的某些操作(例如执行终端命令),并负责实时审查更改。
4.3、Agument 插件的上下文工程架构分析
.90CJUXpP.png)
图解补充:
- 上图中的缓存机制:主要是为了节省查询时间,如果项目数据量级很大的话,是很有必要的,
- 例如:第一个问题查出10个相似得结果,第二个问题假设与第一个问题很相似,那么第二个问题记忆复用第一个问题查询出来的结果
- 在 Augment,我们一次又一次地认识到,提供更相关的上下文能提升产品质量。
- 🌟🌟 这个缓存Agument可能不是缓存上下文检索的文本,而是更加深层的使用(大模型处理的时候会将文本转换为Token),所以缓存的很可能是底部的Token
- 提示词工程不只是技术技能,它是人类意图与机器理解之间的翻译形式。它是在我们希望 AI 系统做什么与它们实际能做什么之间架设桥梁。
五、协同 Agent 的开发方向
1、 🌴 在大模型能力有限的现下,建立”平台“达到协作的目的
协作代理将人类应该做的事情和代理做的事情达到某种平衡,完全的自主代理是未来的方向,至少不是目前的方向,现在是一个过渡的阶段
2、 🌴 足够完整的上下文
借助平台,以此来收集足够完整的上下文,不仅仅是某个问题的上下文,还有用户行为,历史记录等
平台可以提供这个能力和机会,可以收集足够完整的上下文
3、 🌴 提供的工具要的完整信息
工具这个词不要仅限于函数,api等,工具可以是固定的工作流,可以是某个智能体
查询类的工具一般是用来补充上下文
操作类的工具是用来根据模型的输出结果进行现实世界的修改和状态调整的
对于工具的描述足够清晰完整,例如:工具的作用,工具的输入,工具的输出等,越完整越好,提供一份完整的工具说明书
4、 🌴 为每一个工具建立处理准确上下文的流程
刚刚我们可以收集足够多的上下文,多就可以吗?NO
上下文多还不够,要准确,每一个工具需要的上下文都不一样的,要为每个工具建立筛选出来准确上下文的机制
无关的上下文过多,会稀释信号,只有找到最佳的上下文与工具还有模型的平衡点才可获取最佳结果
5、 🌴 输出方式不要“命令式”,而应该“商量式”
大模型输出的结果不要直接使用,而是要经过人审核确认之后才可以使用,大模型在代理协同的方式还是帮助人的定位,例如:cursor中,大模型输出的修改结果,是需要开发者确认之后才可以应用到工作空间的代码中